publications
2026
- IEEE
 Robust Barycenters of Persistence DiagramsKeanu Sisouk, Eloi Tanguy, Julie Delon, and Julien TiernyIEEE Transactions on Visualization and Computer Graphics, Jan 2026
Robust Barycenters of Persistence DiagramsKeanu Sisouk, Eloi Tanguy, Julie Delon, and Julien TiernyIEEE Transactions on Visualization and Computer Graphics, Jan 2026This short paper presents a general approach for computing robust Wasserstein barycenters of persistence diagrams. The classical method consists in computing assignment arithmetic means after finding the optimal transport plans between the barycenter and the persistence diagrams. However, this procedure only works for the transportation cost related to the q-Wasserstein distance Wq when q=2. We adapt an alternative fixed-point method to compute a barycenter diagram for generic transportation costs (q>1), in particular those robust to outliers, q∈(1,2). We show the utility of our work in two applications: (i) the clustering of persistence diagrams on their metric space and (ii) the dictionary encoding of persistence diagrams. In both scenarios, we demonstrate the added robustness to outliers provided by our generalized framework.
@article{sisouk2026robust, author = {Sisouk, Keanu and Tanguy, Eloi and Delon, Julie and Tierny, Julien}, journal = {IEEE Transactions on Visualization and Computer Graphics}, title = {Robust Barycenters of Persistence Diagrams}, year = {2026}, month = jan, selected = true, bibtex_show = true, }
2025
- GRETSI
 Un algorithme de point fixe pour calculer des barycentres robustes entre mesuresEloi Tanguy, Julie Delon, and Nathaël GozlanIn GRETSI, Aug 2025
Un algorithme de point fixe pour calculer des barycentres robustes entre mesuresEloi Tanguy, Julie Delon, and Nathaël GozlanIn GRETSI, Aug 2025@inproceedings{tanguy2025algorithme, title = {{Un algorithme de point fixe pour calculer des barycentres robustes entre mesures}}, author = {Tanguy, Eloi and Delon, Julie and Gozlan, Natha{\"e}l}, url = {https://hal.science/hal-05147707}, booktitle = {{GRETSI}}, address = {Strasbourg, France}, year = {2025}, month = aug, hal_id = {hal-05147707}, hal_version = {v2}, bibtex_show = true } - PREPRINT
 Differentiable Expectation-Maximisation and Applications to Gaussian Mixture Model Optimal TransportSamuel Boïté, Eloi Tanguy, Julie Delon, Agnès Desolneux, and Rémi FlamaryarXiv preprint arXiv:2509.02109, Sep 2025
Differentiable Expectation-Maximisation and Applications to Gaussian Mixture Model Optimal TransportSamuel Boïté, Eloi Tanguy, Julie Delon, Agnès Desolneux, and Rémi FlamaryarXiv preprint arXiv:2509.02109, Sep 2025The Expectation-Maximisation (EM) algorithm is a central tool in statistics and machine learning, widely used for latent-variable models such as Gaussian Mixture Models (GMMs). Despite its ubiquity, EM is typically treated as a non-differentiable black box, preventing its integration into modern learning pipelines where end-to-end gradient propagation is essential. In this work, we present and compare several differentiation strategies for EM, from full automatic differentiation to approximate methods, assessing their accuracy and computational efficiency. As a key application, we leverage this differentiable EM in the computation of the Mixture Wasserstein distance MW2 between GMMs, allowing MW2 to be used as a differentiable loss in imaging and machine learning tasks. To complement our practical use of MW2, we contribute a novel stability result which provides theoretical justification for the use of MW2 with EM, and also introduce a novel unbalanced variant of MW2. Numerical experiments on barycentre computation, colour and style transfer, image generation, and texture synthesis illustrate the versatility of the proposed approach in different settings.
@article{boite2025differentiable, author = {Boïté, Samuel and Tanguy, Eloi and Delon, Julie and Desolneux, Agnès and Flamary, Rémi}, journal = {arXiv preprint arXiv:2509.02109}, title = {Differentiable Expectation-Maximisation and Applications to Gaussian Mixture Model Optimal Transport}, year = {2025}, month = sep, selected = true, bibtex_show = true, } - COCV
 Constrained Approximate Optimal Transport MapsEloi Tanguy, Agnès Desolneux, and Julie DelonESAIM: COCV, Aug 2025
Constrained Approximate Optimal Transport MapsEloi Tanguy, Agnès Desolneux, and Julie DelonESAIM: COCV, Aug 2025We investigate finding a map \(g\)within a function class \(G \)that minimises an Optimal Transport (OT) cost between a target measure \(ν \)and the image by \(g \)of a source measure \(μ \). This is relevant when an OT map from \(μ \)to \(ν \)does not exist or does not satisfy the desired constraints of \(G\). We address existence and uniqueness for generic subclasses of \(L\)-Lipschitz functions, including gradients of (strongly) convex functions and typical Neural Networks. We explore a variant that approaches a transport plan, showing equivalence to a map problem in some cases. For the squared Euclidean cost, we propose alternating minimisation over a transport plan \(\pi \)and map \(g \), with the optimisation over \(g \)being the \(L^2 \)projection on \(G \)of the barycentric mapping \(\overline\pi\). In dimension one, this global problem equates the \(L^2 \)projection of \(\overline\pi^* \)onto \(G \)for an OT plan \(\pi^* \)between \(μ \)and \(ν \), but this does not extend to higher dimensions. We introduce a simple kernel method to find g within a Reproducing Kernel Hilbert Space in the discrete case. Finally, we present numerical methods for \(L\)-Lipschitz gradients of \(\ell\)-strongly convex potentials, and study the convergence of Stochastic Gradient Descent methods for Neural Networks. We finish with an illustration on colour transfer, applying learned maps on new images, and showcasing outlier robustness.
@article{tanguy2025constrained, author = {Tanguy, Eloi and Desolneux, Agn\`es and Delon, Julie}, journal = {ESAIM: COCV}, title = {Constrained Approximate Optimal Transport Maps}, year = {2025}, month = aug, selected = true, bibtex_show = true, url = {https://doi.org/10.1051/cocv/2025057}, } - PREPRINT
 Sliced Transport PlansEloi Tanguy, Laetitia Chapel, and Julie DelonarXiv preprint arXiv:2508.01243, under revision at MCOM, Aug 2025
Sliced Transport PlansEloi Tanguy, Laetitia Chapel, and Julie DelonarXiv preprint arXiv:2508.01243, under revision at MCOM, Aug 2025Since the introduction of the Sliced Wasserstein distance in the literature, its simplicity and efficiency have made it one of the most interesting surrogate for the Wasserstein distance in image processing and machine learning. However, its inability to produce transport plans limits its practical use to applications where only a distance is necessary. Several heuristics have been proposed in the recent years to address this limitation when the probability measures are discrete. In this paper, we propose to study these different propositions by redefining and analysing them rigorously for generic probability measures. Leveraging the ν-based Wasserstein distance and generalised geodesics, we introduce and study the Pivot Sliced Discrepancy, inspired by a recent work by Mahey et al.. We demonstrate its semi-metric properties and its relation to a constrained Kantorovich formulation. In the same way, we generalise and study the recent Expected Sliced plans introduced by Liu et al. for completely generic measures. Our theoretical contributions are supported by numerical experiments on synthetic and real datasets, including colour transfer and shape registration, evaluating the practical relevance of these different solutions.
@article{tanguy2025sliced, author = {Tanguy, Eloi and Chapel, Laetitia and Delon, Julie}, journal = {arXiv preprint arXiv:2508.01243, under revision at MCOM}, title = {Sliced Transport Plans}, year = {2025}, month = aug, selected = true, bibtex_show = true, } - PREPRINT
 Explicit Universal and Approximate-Universal Kernels on Compact Metric SpacesEloi TanguyarXiv preprint arXiv:2506.03661, May 2025
Explicit Universal and Approximate-Universal Kernels on Compact Metric SpacesEloi TanguyarXiv preprint arXiv:2506.03661, May 2025Universal kernels, whose Reproducing Kernel Hilbert Space is dense in the space of continuous functions are of great practical and theoretical interest. In this paper, we introduce an explicit construction of universal kernels on compact metric spaces. We also introduce a notion of approximate universality, and construct tractable kernels that are approximately universal.
@article{tanguy2025constructive, author = {Tanguy, Eloi}, journal = {arXiv preprint arXiv:2506.03661}, title = {Explicit Universal and Approximate-Universal Kernels on Compact Metric Spaces}, year = {2025}, month = may, selected = true, bibtex_show = true, }
2024
- PREPRINT
 Computing Barycentres of Measures for Generic Transport CostsEloi Tanguy, Julie Delon, and Nathaël GozlanarXiv preprint arXiv:2501.04016, under revision at SIMODS, Dec 2024
Computing Barycentres of Measures for Generic Transport CostsEloi Tanguy, Julie Delon, and Nathaël GozlanarXiv preprint arXiv:2501.04016, under revision at SIMODS, Dec 2024Wasserstein barycentres represent average distributions between multiple probability measures for the Wasserstein distance. The numerical computation of Wasserstein barycentres is notoriously challenging. A common approach is to use Sinkhorn iterations, where an entropic regularisation term is introduced to make the problem more manageable. Another approach involves using fixed-point methods, akin to those employed for computing Fréchet means on manifolds. The convergence of such methods for 2-Wasserstein barycentres, specifically with a quadratic cost function and absolutely continuous measures, was studied by Alvarez-Esteban et al. (2016). In this paper, we delve into the main ideas behind this fixed-point method and explore how it can be generalised to accommodate more diverse transport costs and generic probability measures, thereby extending its applicability to a broader range of problems. We show convergence results for this approach and illustrate its numerical behaviour on several barycentre problems.
@article{tanguy2024computing, author = {Tanguy, Eloi and Delon, Julie and Gozlan, Nathaël}, journal = {arXiv preprint arXiv:2501.04016, under revision at SIMODS}, title = {Computing Barycentres of Measures for Generic Transport Costs}, year = {2024}, month = dec, selected = true, bibtex_show = true, } - MCOM
 Properties of Discrete Sliced Wasserstein LossesEloi Tanguy, Rémi Flamary, and Julie DelonMathematics of Computation, Jun 2024
Properties of Discrete Sliced Wasserstein LossesEloi Tanguy, Rémi Flamary, and Julie DelonMathematics of Computation, Jun 2024The Sliced Wasserstein (SW) distance has become a popular alternative to the Wasserstein distance for comparing probability measures. Widespread applications include image processing, domain adaptation and generative modelling, where it is common to optimise some parameters in order to minimise SW, which serves as a loss function between discrete probability measures (since measures admitting densities are numerically unattainable). All these optimisation problems bear the same sub-problem, which is minimising the Sliced Wasserstein energy. In this paper we study the properties of \(E: Y \longmapsto SW_2^2(\gamma_Y, \gamma_Z)\), i.e. the SW distance between two uniform discrete measures with the same amount of points as a function of the support \(Y ∈R^n \times d\)of one of the measures. We investigate the regularity and optimisation properties of this energy, as well as its Monte-Carlo approximation \(E_p\) (estimating the expectation in SW using only \(p\)samples) and show convergence results on the critical points of \(E_p\)to those of \(E\), as well as an almost-sure uniform convergence and a uniform Central Limit result on the process \(E_p\). Finally, we show that in a certain sense, Stochastic Gradient Descent methods minimising \(E\)and \(E_p\)converge towards (Clarke) critical points of these energies.
@article{tanguy2023discrete_sw_losses, author = {Tanguy, Eloi and Flamary, R{\'e}mi and Delon, Julie}, journal = {Mathematics of Computation}, title = {Properties of Discrete Sliced {W}asserstein Losses}, month = jun, year = {2024}, selected = true, bibtex_show = true, url = {https://www.ams.org/journals/mcom/0000-000-00/S0025-5718-2024-03994-7/}, } - CRAS
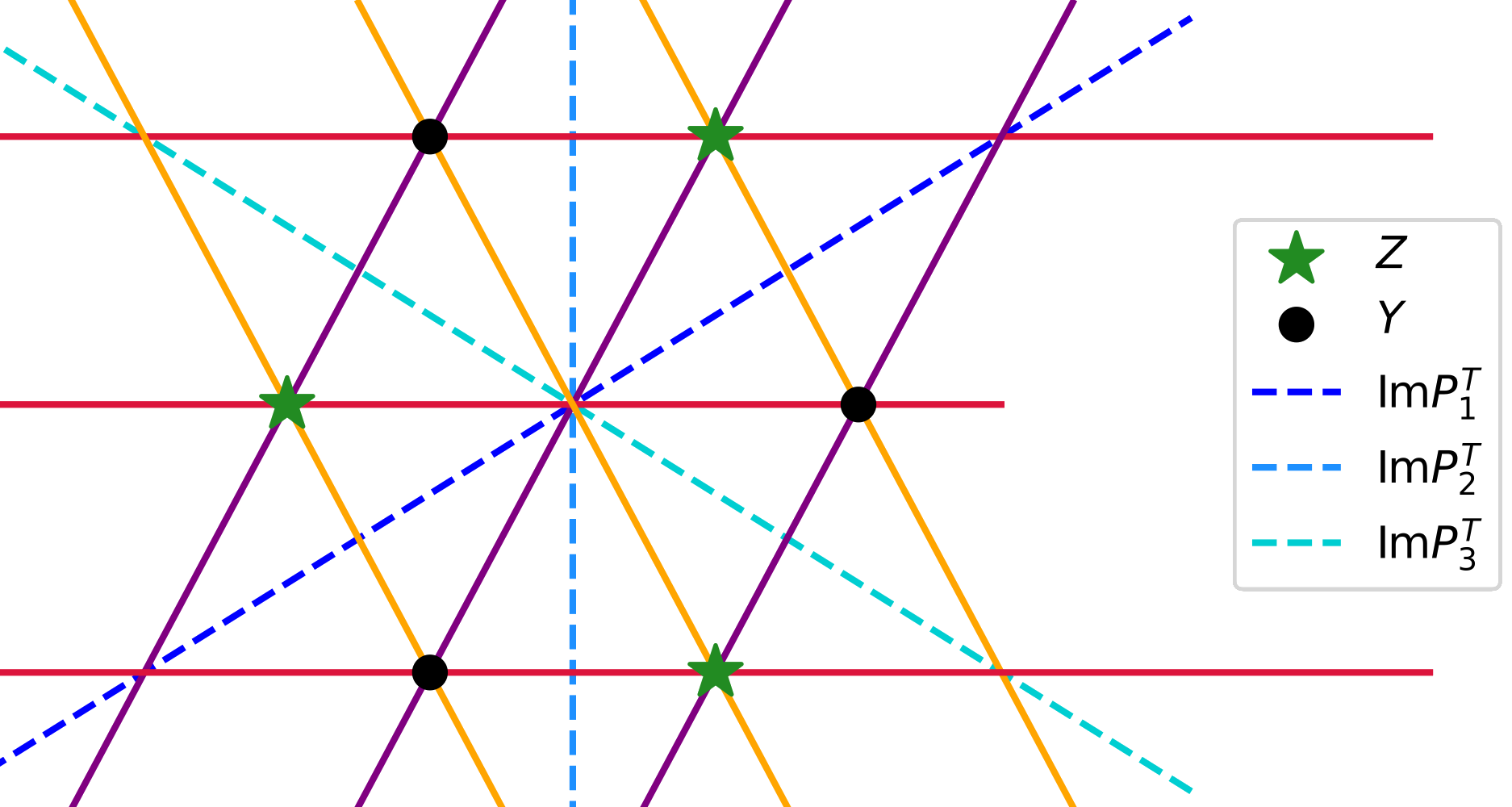 Reconstructing discrete measures from projections. Consequences on the empirical Sliced Wasserstein DistanceEloi Tanguy, Rémi Flamary, and Julie DelonComptes Rendus. Mathématique, 2024
Reconstructing discrete measures from projections. Consequences on the empirical Sliced Wasserstein DistanceEloi Tanguy, Rémi Flamary, and Julie DelonComptes Rendus. Mathématique, 2024This paper deals with the reconstruction of a discrete measure \(\gamma_Z \)on \(R^d\)from the knowledge of its pushforward measures \(P_i\)#\(\gamma_Z\)linear applications \(P_i: R^d →R^h\) (for instance projections onto subspaces). The measure \(\gamma_Z \)being fixed, assuming that the rows of the matrices \(P_i\)are independent realizations of laws which do not give mass to hyperplanes, we show that if \(\sum_i h_i > d\), this reconstruction problem has almost certainly a unique solution. This holds for any number of points in \(\gamma_Z\). A direct consequence of this result is an almost-sure separability property on the empirical Sliced Wasserstein distance.
@article{tanguy2024reconstructing, author = {Tanguy, Eloi and Flamary, R{\'e}mi and Delon, Julie}, journal = {Comptes Rendus. Math\'ematique}, pages = {1121--1129}, title = {Reconstructing discrete measures from projections. Consequences on the empirical Sliced {W}asserstein Distance}, publisher = {Acad\'emie des sciences, Paris}, volume = {362}, year = {2024}, selected = true, bibtex_show = true, doi = {10.5802/crmath.601}, url = {https://comptes-rendus.academie-sciences.fr/mathematique/articles/10.5802/crmath.601/}, }
2023
- TMLRConvergence of SGD for Training Neural Networks with Sliced Wasserstein LossesEloi TanguyTransactions on Machine Learning Research, Oct 2023
Optimal Transport has sparked vivid interest in recent years, in particular thanks to the Wasserstein distance, which provides a geometrically sensible and intuitive way of comparing probability measures. For computational reasons, the Sliced Wasserstein (SW) distance was introduced as an alternative to the Wasserstein distance, and has seen uses for training generative Neural Networks (NNs). While convergence of Stochastic Gradient Descent (SGD) has been observed practically in such a setting, there is to our knowledge no theoretical guarantee for this observation. Leveraging recent works on convergence of SGD on non-smooth and non-convex functions by Bianchi et al. (2022), we aim to bridge that knowledge gap, and provide a realistic context under which fixed-step SGD trajectories for the SW loss on NN parameters converge. More precisely, we show that the trajectories approach the set of (sub)-gradient flow equations as the step decreases. Under stricter assumptions, we show a much stronger convergence result for noised and projected SGD schemes, namely that the long-run limits of the trajectories approach a set of generalised critical points of the loss function.
@article{tanguy2023convergence_sgd_sw_nn, author = {Tanguy, Eloi}, journal = {Transactions on Machine Learning Research}, title = {Convergence of SGD for Training Neural Networks with Sliced {W}asserstein Losses}, year = {2023}, month = oct, selected = true, bibtex_show = true, url = {https://openreview.net/forum?id=aqqfB3p9ZA}, issn = {2835-8856} }
2022
- MASTER THESIS
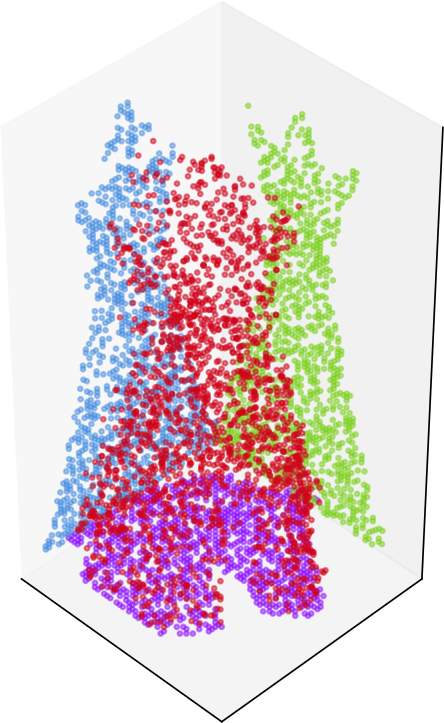 [Report] Generalised Wasserstein BarycentresEloi Tanguy, Julie Delon, and Rémi FlamarySep 2022
[Report] Generalised Wasserstein BarycentresEloi Tanguy, Julie Delon, and Rémi FlamarySep 2022We generalise Wasserstein Barycentres, allowing the computation of barycentres between measures in different spaces. We provide efficient solvers for this new problem, and study a particular case which corresponds to a reconstruction problem. Studying the properties of this problem, we draw partial conclusions on the optima of the discrete Sliced Wasserstein Distance.
@report{reportGWB, title = {[Report] Generalised Wasserstein Barycentres}, author = {Tanguy, Eloi and Delon, Julie and Flamary, Rémi}, year = {2022}, month = sep, selected = true, journal = {Master Thesis}, bibtex_show = true, }